تتمحور هذه الوحدة حول مفهوم استرجاع المعلومات Information Retrieval، وهو ايجاد المحتوى والذي غالبا ما يكون على شكل مستندات documents غير منظمة (مثل النصوص) من بين كم هائل من هذه المستندات التي تكون مخزنة على اجهزة الحاسوب والتي تلبي احتياجات المستخدم من المعلومات. وبدأ البحث في مجال استرجاع المعلومات في السبعينات من القرن الماضي وذلك بالبحث عن البيانات المهيكلة structured data، ولكن حديثا أصبح البحث عن النصوص الحرة free text مثل كتابة نص ما واسترجاع جميع الوثائق التي ورد فيها هذا النص او حتى الوثائق المتعلقة بالموضوع حتى وان لم يرد ذلك النص فيها. مثل عمل جوجل.
- توضح مفهوم استرجاع المعلومات.
- توضح المشاكل اللغوية في استرجاع المعلومات.
- توضح نماذج استرجاع المعلومات الرئيسية.
- مقدمة
- المشاكل اللغوية في استرجاع المعلومات
- نماذج استرجاع المعلومات الرئيسية
مقدمة
استرجاع المعلومات هو ايجاد المحتوى والذي غالبا ما يكون على شكل مستندات documents غير منظمة (مثل النصوص) من بين كم هائل من هذه المستندات التي تكون مخزنة على اجهزة الحاسوب والتي تلبي احتياجات المستخدم من المعلومات.
بدأ البحث في مجال استرجاع المعلومات في السبعينات من القرن الماضي وذلك بالبحث عن البيانات المهيكلة structured data، ولكن حديثا أصبح البحث عن النصوص الحرة free text مثل كتابة نص ما واسترجاع جميع الوثائق التي ورد فيها هذا النص او حتى الوثائق المتعلقة بالموضوع حتى وان لم يرد ذلك النص فيها. مثل عمل جوجل.
نموذج البيانات المهيكلة
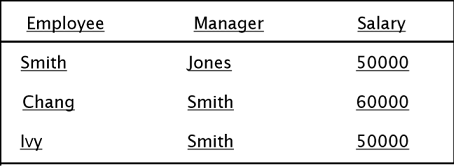
البيانات المهيكلة هي البيانات المنظمة على شكل جداول وتمكننا من الاستعلام عن أرقام في مدى معين او النصوص المتطابقة باستخدام لغات الاستعلام كلغة SQL، مثلاً . Salary < 60000 AND Manager = Smith
نموذج النصوص الحرة to google
البحث عن نصوص حرة في مستندات وملفات وصفحات انترنت غير منظمة على شكل جداول.

المشاكل اللغوية في استرجاع المعلومات
كما نعلم لغة الانسان تتألف من الكلمات والتي تأتي على شكل سلاسل او جمل، باستخدام هذه الكلمات نستطيع التعبير عن أفكارنا والتواصل مع الأخرين. لان الكلمات في أحاديثنا تشير الى أشياء او لها معنى مفهوم بين البشر الذين يتحدثون. ولكن بعض الكلمات في اللغة مترادفه -أي لها نفس المعنى-وبعضها غامض غير مفهوم بشكل واضح .
يسبب استخدام اللغات الطبيعية من اجل استرجاع المعلومات العديد من المشاكل. المشكلة الأساسية تمثلت بما يعرف بمشكلة عدم التعيين “indeterminacy”، وهي مشكلة عدم الوصول لموضوع المستند. ان هذه المشكلة تظهر بسبب تمثيل المواضيع بتراكيب لغوية مختلفة. ان هذه التراكيب اللغوية المختلفة يمكن ان تحمل نفس المعنى وهي مشكلة المترادفات (problem of synonyms)، وبعض التراكيب اللغوية المتشابهة يمكن ان تحمل معاني مختلفة وتدعى هذه المشكلة بمشكلة الغموض (problem of ambiguity). وهناك علاقات دلالية وبنيوية اخرى مختلفة ومعقدة بين التراكيب اللغوية. في الواقع، واحدة من المشاكل الرئيسية التي تواجه المسؤولين عن تطوير التطبيقات اللغوية في نظم استرجاع المعلومات هي مواجهة الكم الهائل من المشاكل الحسابية في المعالجة اللغوية ضمن بيئة معقدة جدا وغير مفهومة بشكل واضح.
من اجل التغلب على مشاكل استخدام اللغات الطبيعية كلغات بحث قام مختصو المعلومات بتطوير عدد من لغات الفهرسة مثل قواميس المترادفات (thesaurus) وعناوين المواضيع (subject headings) للتحكم بالمترادفات والالفاظ المتجانسة وانشاء علاقة بين المصطلحات (terms) لتحديد مفهوم الكلمات بشكل ادق، وتقنيات أخرى كالتحليل الصرفي والتجريد والاقتطاع تستخدم للتحكم بالتغير الصرفي للكلمات.
نماذج استرجاع المعلومات الرئيسية
النماذج الرئيسية التالية والتي تم تطويرها لاسترجاع المعلومات هي: النموذج المنطقي (Boolean model)، النموذج الإحصائي (Statistical model) والذي يتضمن نموذج استرجاع الفضاء الشعاعي (Vector Space Model) والنموذج الاحتمالي (Probabilistic Model)
-
النموذج الأول (المنطقي) يعرف عادة بنموذج التطابق التام “exact match" بينما النموذج الثاني يعرف باسم نموذج أفضل تطابق "best match" الاسترجاع بواسطة الاستعلامات عادة ما يكون أقل من الكمال في ناحيتين:
- الأولى، استرجاع مستندات عديمة الصلة بالاستعلام.
- ثانياً، لا يتم استرجاع جميع المستندات ذات الصلة بالاستعلام.
والمقياسان التاليان يستخدمان عادة في تقييم فعالية نظام الاسترجاع. المقياس الأول يدعى معدل الدقة "precision rate" هو نسبة المستندات ذات الصلة التي تم استرجاعها الى عدد المستندات الكلي المسترجع. المقياس الثاني يدعى معدل الاستدعاء "recall rate” ويساوي نسبة كل المستندات المسترجعة ذات الصلة الى عدد المستندات ذات الصلة الكلي. فإذا اراد الباحث رفع معدل الدقة فعليه ان يقوم بحصر-تضييق-استعلامه، اما إذا اراد رفع معدل الاستدعاء فإنه يقوم بتوسيع الاستعلام.
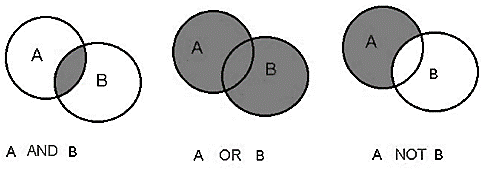
شكل يوضح كيفية عمل خوارزمية الربط البوليني
ورغم ما يتمتع به من بساطة واحكام في منطقه الا ان به الكثير من العيوب والتي تمثل تحديا في استرجاع وترتيب المحتوى داخل محركات البحث، ومن هذه العيوب ما يلي:
- المعيار ذو الحكم الثنائي على درجة الصلة بين الاستعلام ومحتوى الوثيقة: ينظر إلى الكلمات والمفردات الكشفية على انها اما موجودة أو غائبة دون تحديد لدرجات الصلة، مما يحول دون استرجاع جيد وفعال لمحتوى الوثائق. فالمصطلح الكشفي لا يمثل بوزن بين (0،1) كما يحدث في جميع الخوارزميات، بل يحصل على أحد الاحتمالين إما (0) وإما (1).
- يتطلب المنطق البوليني استخدام نفس المصطلحات التي كشف بها محتوى الوثائق للتعبير عن استعلام المستخدم، وذلك لضمان نجاح عملية المقارنة.
- يتطلب المنطلق البوليني تدريباً المستخدمين على صياغة الاستفسارات، لأنه يختلف عن اللغة الطبيعية في الاستخدام.
- نجد المعامل AND، يحد من عملية البحث، فالبحث عن A AND B AND C، سوف يستبعد محتوى الوثائق التي لا تشتمل على المصطلحات الثلاثة مجتمعة، مع أنه يحتمل أن تكون وثيقة تشتمل على اثنين فقط ذات جدوى المستخدم. وبالتالي نجد أن المعامل ANDغالباً ما يؤدي إلى فشل عملية البحث.
- التعبيرات والروابط البولينية تتسم بأن لها دلالات محددة في كثير من الأحيان، فرغم ما تتسم بها من بساطة الا انها ليست بسيطة في التعبير عن الحاجات المعلوماتية. ففي الواقع نجد أن معظم المستخدمين يجدون صعوبة في التعبير عن مطالبهم وحاجاتهم في ظل استخدام التعبيرات المنطقية أو البولينية.
يعد أحد أهم نماذج الترتيب في استرجاع المحتوى استخداما، وقد كان ل "بيتر لون" الفضل في تطوير منطقية الاعتماد على الموجهات، حيث كان أول من اقترح استخدام النهج الاحصائي في البحث عن المعلومات عام 1957 معتمدا على معيار التماثل بين الاستفسارات والوثائق.
فوفقا للنموذج الاحصائي، ينظر إلى محتوى الوثيقة على انه حقيبة كلمات Bag of words، بمعنى أن محتوى الوثيقة يشتمل على مصطلحات غير مرتبة وذات ترددية غير منتظمة داخل محتوى الوثيقة.
كانت الفكرة الرئيسية التي بني عليها نموذج الموجهات في الفراغ، أن استخدام الوزن الثنائي (يتصل أو لا يتصل (0،1)) يحد جدا من عملية الاسترجاع (كما يفعل النموذج البوليني) والترتيب الطبقي للنتائج، وبناءً عليه قدم هذا النموذج اطار عمل جديد يعتمد على ما يعرف بالمطابقة الجزئية (اي ان درجة اتصال أو عدم اتصال الوثيقة بالاستفسار يحدد من خلال أوزان متفاوتة بين قيمتين أدناها يرمز له بالرقم 0 وأعلاها يرمز له بالرقم 1 (0,0.1,0.2,0.3….1 ) ويتم ذلك من خلال مجموعة من المعادلات الخاصة بوزن المصطلح بحيث تستخدم هذه الاوزان في نهاية المطاف لحساب درجة التشابه والتماثل بين كل من الوثيقة المخزنة في النظام وبين استعلام المستخدم).
في نموذج فراغ الموجهات، تحسب درجة صلة محتوى الوثيقة بالاستعلام من خلال تحديد درجة التشابه بينهما، حيث يمثل كلا من محتوى الوثيقة والاستفسار في صورة موجهات في فراغ متعدد الابعاد كما هو موضح في الشكل التالي:
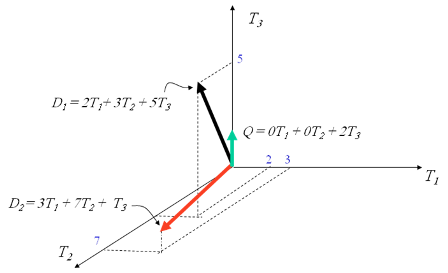
توضح المنهجيات المختلفة لحساب جيب الزاوية بين الاستفسار والوثيقة.
dj= (w1,j,w2,j,...,wt,j)
q= (w1,q,w2,q,...,wt,q)
حيث ينطوي كل موجه على اوزان غير ثنائية للمصطلحات الكشفية في كلا من محتوى الوثيقة والاستعلام والتي يشار اليها بالرمز w1. وتحسب درجة الصلة للوثائق من خلال مقارنة انحراف الزوايا بين كل من موجه الوثيقة وموجه الاستعلام كما هو موضح من خلال المعادلة الاتية:
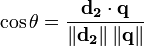
- الأساس الرياضي الذي يعتمد عليه هذا النموذج:
يمكن ان توصف العلاقة بين محتوى الوثيقة D والمصطلح Tمن خلال المصفوفة tf -idfكمعيار كمي يشتمل على محورين اساسين:-
المحور الأول: هو تردد المصطلح TFويشير إلى عدد مرات ظهور المصطلح t في محتوى الوثيقة d وتأتي المعادلة لحساب تردد المصطلح على هذا النحو:
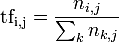
- حيث تشيرtfi,j إلى حساب تردد المصطلح.
- تشير ni,j إلى عدد مرات ظهور المصطلح tiفي محتوى الوثيقة dj.
- وتشير k nk,j∑إلى مجموع عدد المصطلحات في اجمالي الوثيقة.
- مثال اذا افترضنا ان وثيقة ما تتكون من 100 مصطلح، ويظهر مصطلح المكتبات 4 مرات في الوثيقة فإن المعادلة ستكون 4/100)) =0.04
-
المحور الثاني: هو تردد الوثيقة العكسي، والذي يعمل على حساب نسبة اجمالي عدد الوثائق المخزنة في النظام إلى عدد الوثائق التي تشتمل على المصطلح Tوتظهر معادلته على هذا النحو:
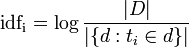
- تشير idfi إلى حساب تردد الوثيقة العكسي.
- بينما تشير logإلى حساب لوغارتيم ناتج القسمة.
- وتشير | D |إلى اجمالي عدد الوثائق في النظام.
- وتشير
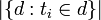 إلى عدد الوثائق التي يظهر فيها المصطلح ti.
إلى عدد الوثائق التي يظهر فيها المصطلح ti.
-
المحور الأول: هو تردد المصطلح TFويشير إلى عدد مرات ظهور المصطلح t في محتوى الوثيقة d وتأتي المعادلة لحساب تردد المصطلح على هذا النحو:
وتبعا للمثال السابق، فإذا افترضنا أن عدد الوثائق المختزنة في النظام تبلغ 1000000وثيقة ويظهر مصطلح المكتبات في 1000 وثيقة من إجمالي عدد الوثائق وبالتالي يحسب log(1000000/1000)=3.
ويحسب معدل التردد العام للوثيقة من خلال حاصل ضرب تردد المصطلحXتردد الوثيقة المعكوس المعادلة الاتية:
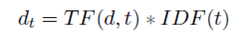
ومن خلال المثال السابق تكون المعادلة 0.04X3=0.12اي ان رتبة الوثيقة يساوي 0.12، ولعل من الملاحظ ان اجمالي القيم ستأتي منحصرة بين رقمي 1 و 0. وعليه يحسب جيب الزاوية الخاصة بالتشابه بين الوثيقة والاستفسار من خلال المعادلة الاتية:
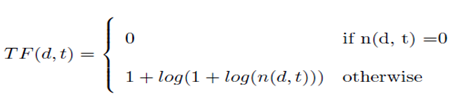
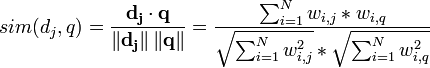
ان عيوب هذا النموذج تمثل تحديا كبيرا في استرجاع المحتوى في محركات البحث والتي تتمثل في اعتماده وبشكل أساسي على المضاهاة المعجمية Lexical، بحيث يقوم باسترجاع محتوى الوثائق التي تستخدم الكلمات الكشفية التي وردت في استفسار المستخدم، واعتباره أكثر محتوى الوثائق صلة بالموضوع، وعليه فان الاسترجاع وفقا للمضاهاة اللغوية يحتوي على مشكلتين أساسيتين:
- الترادف اللغوي Synonym: ناتجة من امكانية استخدام نفس المفهوم ولكن بعبارة او كلمة اخرى. فعند السؤال مثلا عن المساجد لا تظهر النتائج التي تشتمل على لفظة الجوامع.
- التجانس اللغوي Polysemy: اما التجانس فينتج من أن الكلمة الواحدة قد تحظى بأكثر من معنى في سياقات مختلفة. ومثالا على ذلك، قد يسترجع المحتوى عن موضوع القروض ومحتوى اخر يشتمل على اسم صلاح الدين ومحتوى اخر عن الدين الاسلامي نظرا لاستخدام لفظة الدين.
وعليه فإن استخدام المضاهاة اللغوية يؤدي إلى استرجاع محتوى قد لا يتصل باستعلام المستخدم، فضلا على تعامله مع الكلمات في صورة فردية دون النظر إلى السياق[3].
وتمثل مفهوم هذا النموذج في أن مجموعة الوثائق المخزنة في نظام استرجاع المعلومات تنقسم إلى مجموعتين ثنائيتين مستقلتين عن بعضهما البعض، المجموعة الاولى تعرف بمجموعة الصلة والتي يتسم محتواها بالصلة بالاستفسار، والمجموعة الاخرى تعرف بمجموعة اللاصلة والتي يتسم محتواها بعدم الصلة بالاستفسار.
تمثل جوهر هذا النموذج في سؤال منطقي وهو
"ماهي احتمالية صلة وثيقة محددة باستعلام محدد؟!"
من خلال هذا السؤال تبلورت رؤية هذا النموذج في قياس وتحديد الوثائق وفقا لاحتمالية صلتها باستعلام.
إن الفكرة الاساسية لهذا النموذج تتمثل في فرضية احتمال أن نظام استرجاع المعلومات يشتمل على وثائق تتصل باستفسار المستخدم تمام الصلة، وهناك مجموعة اخرى بعيدة عن هذه الصلة، فوفقا لهذا النموذج تسمى مجموعة الوثائق ذات الصلة بمجموعة الجواب المثالي ideal answer set، ﻓﻌﻠﻰ ﺴﺒﻴل ﺍﻟﻤﺜﺎل ﻗ ﺩ ﻴﺘﻡ ﺘﺤﺩﻴﺩ ﺍﻟﻭﺜﻴﻘﺔ ﺫﺍﺕ ﺍﻟﺼﻠﺔ ﻋﻥ ﻁﺭﻴﻕ ﺘﻭﻅﻴﻑ ﺍﻟﻤﻌﻠﻭﻤﺎﺕ ﺍﻟﺘﺎﺭﻴﺨﻴﺔ ﻻﺴﺘﺨﺩﺍﻡ ﺘﻠﻙ ﺍﻟﻭﺜﻴﻘﺔ ﻻﺤﺘﺴﺎﺏ ﻭﺇﺤﺼﺎﺀ ﺍﺤﺘﻤﺎﻻﺕ ﺼﻠﺘﻬﺎ ﺒﺎﻻﺴﺘﻔﺴﺎﺭ. ﻭﺍﻟﻤﻘﺼﻭﺩ ﺒﺫﻟﻙ ﺃﻥ ﻴﺘﻡ ﺘﺘﺒﻊ ﻋﺩﺩ ﺍﻟﻤﺭﺍﺕ ﺍﻟﺘﻲ ﺤﻜﻡ ﻓﻴﻬﺎ ﺍﻟﻤﺴﺘﻔﻴﺩﻭﻥ ﻋﻠﻰ ﺍﻟﻭﺜﻴﻘﺔ ﺒﺄﻨﻬﺎ ﺫﺍﺕ ﺼﻠﺔ ﺒﺎﻻﺴﺘﻔﺴﺎﺭ ﻓﻲ ﺤﺎﻟﺔ ﺍﺴﺘﺨﺩﺍﻤﻬﻡ ﻟﻨﻔﺱ ﻤﺼﻁﻠﺢ ﺍ ﻟﺒﺤﺙ، ﻭﺒﻤﻌﻨﻰ ﺁﺨﺭ ﺇﺫﺍ ﺍﺴﺘﺨﺩﻡ ﻤﺴﺘﻔﻴﺩ ﻤﺼﻁﻠﺢ ﺒﺤﺙ ﻻﺴﺘﺭﺠﺎﻉ ﻭﺜﺎﺌﻕ، ﻭﺤﻜﻡ ﻋﻠﻰ ﻭﺜﻴﻘﺔ ﻤﻥ ﺒﻴﻨﻬﺎ ﻋﻠﻰ ﺃﻨﻬﺎ ﺫﺍﺕ ﺼﻠﺔ ﺒﺎﻟﻤﻭﻀﻭﻉ، ﻭﺘﻜﺭﺭ ﻫﺫﺍ ﺍﻟﺤﻜﻡ ﻋﻠﻰ ﺍﻟﻭﺜﻴﻘﺔ ﻤﻥ ﻗﺒل ﺃﺸﺨﺎﺹ ﺁﺨﺭﻴﻥ ﺍﺴﺘﺨﺩﻤﻭﺍ ﻨﻔﺱ ﻤﺼﻁﻠﺢ ﺍﻟﺒﺤﺙ، ﻓﺈﻨﻪ ﻴﻤﻜﻥ ﺍﻟﺤﻜﻡ ﻋﻠﻰ ﺍﻟﻭﺜﻴﻘﺔ ﺒﺄﻨﻬﺎ ﺫﺍﺕ ﺼﻠﺔ ﺒﺎﻻﺴﺘﻔﺴﺎﺭ .ﻁﺭﻴﻘ ﻭﻴﺫﻜﺭ ﺃﻥ ﻫﺫﻩ ﺔ ﻭﺍﺤﺩﺓ ﻤﻥ ﺒﻴﻥ ﻁﺭﻕ ﻤﺘﻌﺩﺩﺓ ﺘﺴﺘﺨﺩﻡ ﻟﺘﺤﺩﻴﺩ ﺍﺤﺘﻤﺎﻻﺕ ﺼﻠﺔ ﺍﻟﻭﺜﻴﻘﺔ ﺒﺎﻻﺴﺘﻔﺴﺎﺭ.
تتخذ معادلة النموذج الاحتمالي هذا الشكل:
- q للإشارة إلى استفسار المستخدم.
- dj للإشارة إلى الوثائق في نظام استرجاع المعلومات.
- R للإشارة إلى مجموعة الاجابة المثلى.
- ~R للإشارة إلى الوثائق التي لا صلة لها
- P(R|dj) للإشارة إلى احتمالية ظهور مجموعة الاجابة المثلى من اجمالي وثائق النظام.
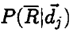 للإشارة إلى احتمالية ظهور الوثائق ذات عدم الصلة ضمن اجمالي وثائق النظام.
للإشارة إلى احتمالية ظهور الوثائق ذات عدم الصلة ضمن اجمالي وثائق النظام.
- Sim للإشارة إلى حساب درجة التشابه والتماثل.
بحيث تتخذ المعادلة هذه الصورة لحساب احتمالية صلة الوثائق او عدم صلتها:
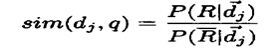
ووفقا لقاعدة Bayes[6] تتخذ المعادلة هذه الصورة:
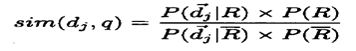
أن ما يعيب هذا النموذج ويمثل تحديا في استرجاع وترتيب المحتوى في محركات البحث يكمن في:
- الحاجة إلى التخمين للفصل الأولي لمحتوى الوثائق في مجموعتين مجموعة ذات صلة ومجموعة لا تتسم بالصلة.
- إن هذه الطريقة لا تأخذ في الاعتبار وتيرة تردد المصطلحات الكشفية داخل الوثائق (مما يرجعنا إلى نظرية الحكم الثنائي الخاصة بالنموذج البوليني).[7]
إن نماذج الاسترجاع -السابق ذكرها -تعتمد وبشكل اساسي على الاسترجاع من خلال اختزال محتوى كلا من الاستعلام والوثيقة في مجموعة من المصطلحات الكشفية أو الكلمات المفتاحية.
ثم يتم بعد ذلك إلى قياس درجة التشابه بين كل منهما، ثم الاسترجاع وفقا لهذا الاساس. وتعرف هذه المنهجية باسم الاسترجاع وفقا للتشابه المعجمي lexical matching method أي من خلال الاعتماد على المقارنة بين الاحرف المكونة للمصطلحات الكشفية الواردة في كل من الوثيقة والاستفسار. ووفقا لهذه المنهجية السابقة يتسم اداء ومعدل الاسترجاع في محركات البحث بالفقر، وعدم الدقة، وهي الأسباب وراء تدني معدلات الاسترجاع والترتيب والمرجعية في ذلك تعود إلى سببين:
ففي العادة تتوافر العديد من المصطلحات التي يمكن ان يستخدمها المستخدم في التعبير عن حاجته البحثية او المفهوم المجرد لاستفساره، فمن الممكن ان يقوم المستخدم بالتعبير عن مفهوم مجرد بلفظة الجوامع مثلا في حين أن مستخدم اخر يعبر عنها بلفظة المساجد، في حين أن كلا اللفظين يشيرا إلى مفهوم واحد وهو دور العبادة لإقامة الصلاة عند المسلمين، ووفقا لمنهجية المضاهاة المعجمية فإن بعض الوثائق ذات الصلة التي لم تكشف وفقا للمصطلحات الكشفية لدى المستخدم قد لا تسترجع. ومن ناحية اخرى قد تسترجع العديد من الوثائق التي لا تتصل بالاستفسار مثل البحث عن لفظة الدين ، فقد ينطوي الأمر على ان تسترجع وثائق موضوعها الديانات، واخرى موضوعها القروض والاقتراض، واخرى تحتوي لفظة الدين كاسم شخص كاسم صلاح الدين او عماد الدين.
فالأفكار التي ترد في نصوص الوثائق أقرب ان توصف من خلال المفهوم بدلا من أن توصف من خلال الالفاظ، وقد عرفت هذه المنهجية باسم التكشيف الدلالي الكامن Latent semantic indexing. يعتمد النموذج الدلالي الكامن على تحليل درجة العلاقة الدلالية بين محتوى الوثائق من خلال معادلات احصائية. فوفقا لهذه المنهجية فأن محرك البحث يقوم باسترجاع محتوى الوثائق ذات الصلة بمفهوم الاستفسار، وليس وفقا لتشابه الكلمات المفتاحية حتى ولو لم تشتمل هذه الوثائق على مصطلحات الاستفسار، كما هو موضح في الشكل التالي:
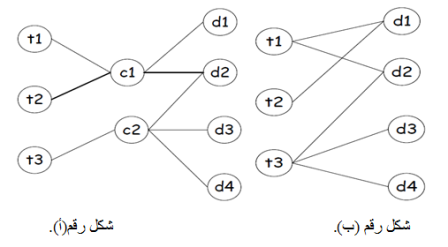
يوضح هذا الشكل منهجية عمل نموذج التكشيف الدلالي الكامن.
يوضح هذا الشكل منهجية عمل التكشيف وفقا للمضاهاة المعجمية والتكشيف وفقا للمفهوم، حيث في الشكل رقم (أ) يتضح ان كل لفظ يقابله مجموعة من الوثائق اما في الشكل (ب) فان الوثائق ترتبط بالمفاهيم التي تدل عليها مجموعة من الالفاظ المختلفة.
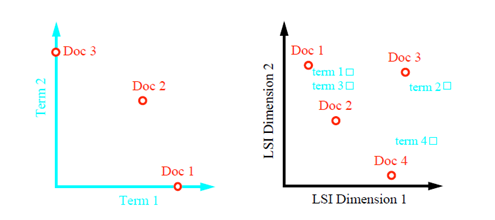
الشكل اعلاه يقدم مقارنة بين نموذج الاسترجاع فراغ الموجهات وبين نموذج الاسترجاع الدلالي الكامن.
ففي اغلب نماذج الاسترجاع يتم رصد محتوى الوثائق وفقا للمصطلحات المعبرة عنها، أما في النموذج الدلالي فالوثائق ترصد وفقا للمفاهيم ثم تحصر الالفاظ التي تحدد موضوع الوثائق من داخلها كما هو موضح في الشكل السابق.
إن عيوب هذا النموذج والتي تعتبر تحديا في استرجاع وترتيب المحتوى في محركات البحث: هو قدرته المحدودة في التعامل مع الاعداد الضخمة من الوثائق كما هو الحال في بالنسبة إلى حجم مصادر الشبكة العنكبوتية[9]
تعتمد هذه الخوارزمية على اكتشاف وترتيب محتوى الوثيقة ذات الصلة بموضوع محدد، بمعنى ان هذه الخوارزمية تعتمد على أن يوجه المستخدم اولا الاستعلام لاداه البحث ثم تسترجع النتائج من الكشاف index او قاعدة البيانات لبدء مرحلة الترتيب للنتائج وفقا لعنصرين اساسين هما:
- المواقع المحورية Hubs Nodes: وهي المواقع التي تشتمل على محتوى يصدر منه الرابط في اشارة منها لمواقع الاستنادية.
- المواقع الاستنادية او ذات الموثقية Authorities Nodes: ويقصد بها المواقع التي يرد اليها الرابط من قبل المواقع المحورية كما هو موضح في الشكل التالي.

شكل يوضح بنية المواقع المحورية والمواقع الاستنادية
يتم تحديد المواقع الموثوقية من خلال تتبع الروابط من نقاط محورية محددة تكون بمثابة دليل موثوق به لمحرك البحث ثم يتم تتبع الروابط التي يشير فيها لمواقع اخرى، فلو افترضنا ان الصفحة I بمثابة صفحة ذات موثقيه authority للاستفسار المقدم لمحرك البحث عن " مصانع السيارات" حيث أنها تشتمل على معلومات قيمة عن الموضوع المراد الاستفسار عنه، حيث تعد الصفحات الرسمية لمنتجي السيارات بمثابة صفحات استناديه ذات موثوقية لهذه العملية البحثية كموقع فولكسفاجن وتويوتا ومرسيدس وغيرها كما تعد مواقع وصفحات وكلاء المبيعات لهذه السيارات بمثابة صفحات استناديه ايضا للموضوع المشار اليه كما هو موضح في الشكل التالي:
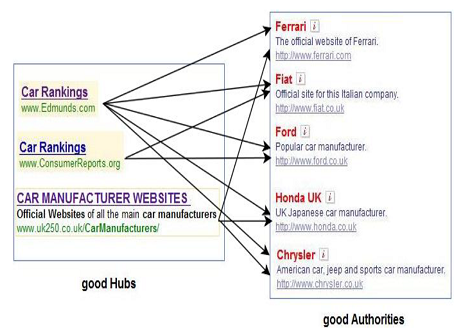
شكل يوضح المثال السابق
وتتمثل العلاقة بينهما في علاقة تبادلية تعزز بعضها البعض، بمعنى أن المواقع المحورية ذات الجودة العالية تشير إلى المواقع الاستنادية الجيدة والعكس ايضا. وعليه تعمل هذه الخوارزمية على تحديد درجة خاصية محورية الوثيقة ودرجة اخرى لإستنادية نفس الوثيقة، ويحدد على اساسهما رتبة الموقع في قائمة النتائج:
وعلية تحسب درجة الموثوقية والنقطة المحورية للوثيقة p على النحو الاتي:

حيث تشير nإلى مجموع عدد المواقع التي ترتبط بالصفحة p، أما i فتشير إلى الصفحة المرتبطة ب p بشكل مباشر[10].
طور هذا النموذج على يد كلا من Sergey Brin و Lawrence Pageعام 1997، وقد عرف هذا النموذج ب" بانها المنهجية التي تعني بحساب رتبة محتوى كل صفحة على العنكبوتية اعتمادا على نمذجة العنكبوتية في مخطط بياني قائم على الروابط والمواقع". ولقياس جدوى هذه الخوارزمية قام كل من Brin و Page بتصميم محرك البحث الشهير Google.
أن الجانب الذي التفتت اليه هذه الخوارزمية هو النظر إلى الكيف دون الكم، بمعنى الاخذ في الاعتبار جودة الروابط بدلا من النظر إلى عدد الروابط، فتستند هذه الخوارزمية على مبدئين اساسين هما:
- تمثل الروابط مؤشرات جيدة لتحديد اهمية محتوى الوثيقة التي تشير اليها.
- الروابط الصادرة من وثائق تحظى بأهمية في موضوعها تعد مؤشرا جيدا لجودة الوثيقة التي تشير اليها عن الوثيقة التي يشار اليها من قبل وثائق اقل في الاهمية والجودة كما هو موضح في الشكل التالي.
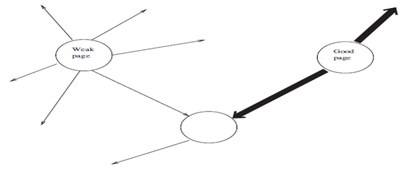
شكل يوضح منهجية PageRank ويوضح دلالة ان الرابط الفائق يكتسب قوة من قوة الصفحة ومحتواها
بداية يجدر الاشارة إلى ان خوارزمية الترتيب الطبقي (the pagerank) صدرت في أكثر من صيغة وأكثر من معادلة متتالية، وسنتعرض في هذا القسم إلى الصيغة البسيطة من هذه المعادلات.
تعتمد خوارزمية الترتيب الطبقي على نظرية احصائية تعرف بنظرية التوزيع الاحتمالي، والتي تعمل على احتمالية تحديد قيمة لمتغير ما (كصفحة عنكبوتية او الرابط) تم اختياره عشوائيا، هذه القيمة هي الاهمية والتي يمكن ان تتراوح ما بين قيمتين اساسيتين هما (0 و 1).
ولنفترض ان لدينا بنية بيانية لشبكة عنكبوتية تتكون من 4 نقاط (NODES) (أربع صفحات) A,B,C and D وأن أهمية هذه الصفحات تتوزع بالتساوي بينهم – أي تقسيم رقم 1 الذي يشير إلى وجود اهمية للبنية البيانية للشبكة بالتساوي – فيكون نصيب كل صفحة هو 0.25، ولنفترض أن بين هذه الصفحات مجموعة من الروابط والتي سيتم الاعتماد عليها لحساب رتبة الصفحة A، هذه الروابط تتمثل في الشكل التالي:
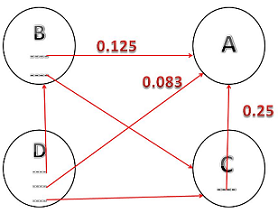
شكل يوضح كيفية حساب رتبة الصفحة من خلال الرابط
حيث تشير كل من الروابط الموجودة في الصفحات B,C,D إلى الصفحة A كما هو موضح في الشكل، مع الآخذ في الاعتبار أن الصفحة A تحسب رتبتها من خلال قيمة الرابط الذي يشير اليها فإذا كانت الصفحة B تحظى بقيمة مقدارها 0,25 موزعة هذه القيمة على رابطين فإن قيمة الصفحة B بالنسبة إلى الصفحة A هي: 0.25/2=0.125وتحسب قيمة الرتبة A من خلال المعادلة الاتية:
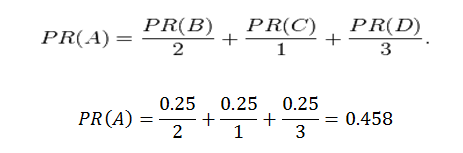
ومن ثم تكون رتبة الوثيقة A في موضوع تخصصها 0.458على صعيد الشبكة العنكبوتية.
هناك العديد من محركات البحث التي تمكنك من البحث عن المصادر المفتوحة والمنشورة وفق تراخيص المشاع الإبداعي ومن أشهرها:
يتيح محرك المشاع الإبداعي للمستخدمين البحث عن كافة أنواع الموارد التعليمية المفتوحة، مثل المقالات، الصور، الفيديو، الصوتيات وغيرها، ويقوم باسترجاع النتائج من عدة محركات بحث أخرى مثل (جوجل)، (يوتيوب)، (فليكر)، (ويكيبيديا) وغيرها، ويمكن تحديد النتائج وفق نوع ترخيص المشاع الإبداعي المنشورة به.
عزيزي المتعلم، شاهد الفيديو لتوضيح كيفية البحث عن المصادر المفتوحة وفق تراخيص المشاع الإبداعي باستخدام محرك المشاع الإبداعي.
يتيح محرك جوجل للمستخدمين البحث عن الموارد التعليمية المفتوحة وفق تراخيص المشاع الإبداعي ويمكن تحديد النتائج وفق نوع ترخيص المشاع الإبداعي المنشورة به.
عزيزي المتعلم، شاهد الفيديو لتوضيح كيفية البحث عن الموارد التعليمية المفتوحة وفق تراخيص المشاع الإبداعي باستخدام محرك البحث جوجل.
يتيح محرك بحث يوتيوب للمستخدمين البحث عن الفيديوهات المنشورة بتراخيص المشاع الإبداعي ويمكن تحديد النتائج وفق نوع ترخيص المشاع الإبداعي المنشورة به.
عزيزي المتعلم، شاهد الفيديو لتوضيح كيفية البحث عن الفيديوهات المنشورة بتراخيص المشاع الإبداعي باستخدام محرك البحث يوتيوب.
- مورد تعليمي يسمح بإعادة استخدامه والتعديل عليه دون ذكر صاحب العمل.
- مورد تعليمي يسمح بإعادة استخدامه والتعديل عليه بشرط ذكر صاحب العمل.
- مورد تعليمي يسمح بإعادة استخدامه بشرط ذكر صاحب العمل وعدم التعديل.
- ما هو محرك البحث؟
- أهمية محركات البحث
- آلية عمل محرك البحث على الويب
مقدمة
محرك البحث هو نظام مخصص للبحث عن المعلومات على شبكة الانترنت. يستقبل محرك البحث الاستعلامات من المستخدمين ويقوم بمقارنتها (باستخدام خوارزميات معينة) مع فهرس index قام بإنشائه مسبقا لاختبار المعلومات ذات الصلة ومن ثم ً عرضها للمستخدم على شكل قائمة من النتائج يعرف بـ صفحات نتائج محرك البحث Search Engine Results Pages SERPs.
توالى ظهور محركات البحث بعد انتشار الانترنت، ومنها دليل Yahoo! عام 1994, الذي لم يكن محرك بحث بحد ذاته، حيث بقيت Yahoo! معتمدة على مصادر خارجية للبحث على شبكة الويب حتى عام 2002 حيث طرحت محرك بحث خاص بها . العمل على محرك البحث العملاق حاليا بدأ عام 1996 وتم حجز النطاق google.com عام 1997.
المكتبة الإلكترونية
بلغ عدد المواقع على الويب في نهاية عام2012 حوالي634 مليون موقع، منها51 مليون موقع تم إضافته في عام2012 فقط. بينما تضيف مجموعة WordPress فقط 59.4 مليون موقع، ويساهم مستخدموها في إضافة 500,000 منشور و 400,000 تعليق يوميا. يتم تحميل ما يعادل 2.5 بليون صورة شهريا إلى موقع التواصل الاجتماعي Facebook. في حين يضم موقع Tumblr 87 مليون مدونة.
هذه الأرقام ليست بسيطة، هناك تزايد هائل في حجم المعلومات، وحاجة المستخدم الفورية لهذه المعلومات. محرك البحث لن يقدم المعلومة فقط بل سيقدم أفضل معلومة نسبيا. ففي حين قد لا يكون مصدر المعلومة موثوقا ًعلى الانترنت تقوم بعض محركات البحث بتطبيق خوارزميات ذكية تدرس سلوك المستخدمين الآخرين لزيادة أو إنقاص تقييم بعض الصفحات وعرضها بأولويات متفاوتة حسب مصداقيتها.
هناك أيضا مستخدمون مؤذون على شبكة الانترنت قد يضعون محتوى وهمي أو مضر للمستخدمين الآخرين. يقوم محرك البحث تلقائيا بفلترة المحتوى المؤذي أو غير المفيد حسب سلوك المستخدمين السابقين أو حسب تقييم بعض شركات مضادات الفيروسات والملفات المشبوهة.
المكتبة الافتراضية
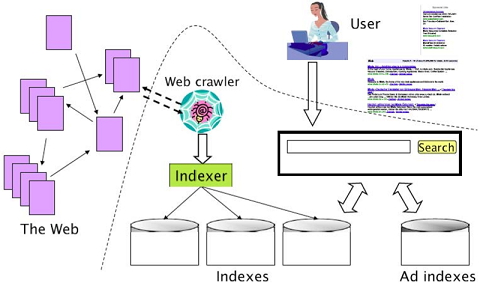
يقوم محرك البحث بإرسال برامج صغيرة تدعى Spiders أو Crawlers تقوم هذه البرامج بتحميل صفحات خادم ما وتفقد كل الروابط فيها وجمع كل المعلومات الممكنة عن هذه الصفحات، تعود المعلومات التي جمعتها Crawlers لتتم فهرستها من قبل المفهرس Indexer ومن ثم ترتيبها وتخزينها في فهرس ذكي. عندما يرد استعلام إلى محرك البحث من قبل المستخدم، يقوم المحرك بالبحث فقط في الفهرس ويرتب النتائج حسب أهميتها، وأولويتها، وصلتها بعملية البحث ومن ثم يعرضها على المستخدمين.
-
Crawling
- Crawler: هو عبارة عن Web bot او Internet bot يقوم بتصفح الانترنت بشكل منهجي بغرض الفهرسة.
- bot: هو تصغير لـ robot، هو برنامج يعمل كعميل لبرنامج آخر ليحاكي بذلك سلوك المستخدم، يؤدي مهام عادة ما تكون بسيطة وتكرارية بمعدل كبير لا يستطيع أن يقوم به الإنسان لوحده.
- Internet bot: هو تطبيق برمجي يقوم بأداء مهام مؤتمتة على شبكة الانترنت.
- آلية عمل الـ Crawler
ينظم الـ Crawler مجموعة كبيرة من عناوين الانترنت URLs يقوم بطلبها وتحميلها بشكل متتالي حسب مجدوِل زمني. يبحث في كل منها عن المعلومات التي يحتاجها فيخزنها لتتم فهرستها لاحقا، ومن ثم يقوم باستخراج كل الروابط الموجودة في الصفحة التي قام بتحميلها وإضافتها إلى مجموعة الصفحات التي سيقوم بزيارتها.
يبحث الـ Crawler عن المعلومات في الصفحات التي يزورها في المصادر التالية:- عنوان الموقع website URL .
- عنوان الصفحة web page title.
- أمارة البيانات الإضافية في meta tag information: HTML .
- محتوى الصفحة web page content .
- الروابط على الصفحة links on the page.
- سياسات عمل الـ: Crawler
يحدد سلوك الـ Crawler بالسياسات التالية:- سياسة الاختيار: : لتحديد الصفحات التي يتم تحميلها، لا يمكن للـ Crawler أن يقوم بتحميل جميع الصفحات، خاصة أن بعض خادمات الويب قد لا ترغب بأن يتم إدراج صفحات معينة في فهرس محرك البحث، كما أن تحميل بعض الصفحات قد يؤدي إلى خلل في عمل الـ Crawler.
- سياسة الاختيار: لتحديد الصفحات التي يتم تحميلها، لا يمكن للـ Crawler أن يقوم بتحميل جميع الصفحات، خاصة أن بعض خادمات الويب قد لا ترغب بأن يتم إدراج صفحات معينة في فهرس محرك البحث، كما أن تحميل بعض الصفحات قد يؤدي إلى خلل في عمل الـ Crawler.
- سياسة التهذيب: لتجنب التحميل الزائد لخادمات الويب وحماية الـ Crawler من الوقوع في فخ بعض المخدمات. (حيث أن الـ Crawler يقوم بطلب عدة صفحات من الخادم خلال زمن قصير جدا فمن السهل جدا ً إغراق الخادم إذا كان يتعرض لطلبات من عدة Crawler في وقت واحد، "المهذب" يناوب بين المخدمات المختلفة ولا يطلب مستندات من الخادم نفسه إلا كل بضع ثواني).
- سياسة التفرع: للتنسيق بين الـ Web Crawler الموزعين، حيث أن كل محرك يملك عدة Crawlers بحث فيجب الانتباه إلى أن لا يتم استهداف مخدم واحد في وقت واحد، ولا يتم طلب الصفحة نفسها من قبل أكثر من Crawler واحد.
-
فخ الـ Crawler
قد تستخدم برمجيات الـCrawler لأسباب مؤذية. كهجومات حجب الخدمة Denial of service او الاغراق. لذلك تلجأ خادمات الويب إلى "نصب أفخاخ" لهكذا Crawler تودي لإدخاله في حلقة لانهائية تؤدي إلى هدر موارده وتقليل إنتاجيته وقد يؤدي إلى انهياره.
- Castillo, C., (2005) “Effective web crawling”, SIGIR Forum, ACM Press,. Volume 39, Number 1, N, pp.55-56.
- Castillo, Carlos. "EffectiveWeb Crawling." Diss. University of Chile, 2004. Web. 12 Oct. 2101. www.chato.cl/papers/crawling_thesis/effective_web_crawling.pdf.
- Vittore Casarosa,” Information Retrieval and Search Engines” http://nmis.isti.cnr.it/casarosa/BDG/, 2018
- reseach Output Managment Online Educational Material (ROMOR) , Access to Digital Libraries, romor.iugaza.edu.ps/moodle/login/index.php#section-5, 2018
- بامفلح فاتم، "استرجاع المعلومات في المكتبات الرقمية دراسة وصفية"، قسم علم المعلومات، 2006
- النشرتي، مؤمن سيد ،"التحديات التي تواجه خوارزميات محركات البحث في استرجاع المحتوى العربي على الشبكة العنكبوتية العالمية: دراسة مسحية تحليلية" . Sybarian journalsالعدد 30، ديسمبر 2012
- محمد عبد المولى محمود .محركات البحث:من اين بدأت وإلى اين انتهت:بنيتها واساليب الاسترجاع. العربية 3000 متاح في : http://www.arabcin.net/arabiaall/index.html
- نبيل علي. العرب وعصر المعلومات.عالم المعرفة.الكويت:المجلس الوطني للثقافة والفنون والاداب.1994.ص333.